Need to think about data model and efficiency of the API.
- JSON / XML / Something Binary
- How much data do I get out of one call?
- Too much data
- Too little data -> many API calls?
- Latency
- Scalability to 1000s of clients
- Load balancing
- Inter operability with many languages
- Authenticatin, Monitoring, Logging
An Evolution of data type
CSV (Comma Separated Values)
Advantegs:
- Easy to parse
- Easy to read
- Easy to make sense of
Disadvantages:
- The data types of elements has to be inferred and is not a guarantee
- Parsing becomes tricky when data contains commas
- Column names may or may not be there
Relational tables definitions
Advantages:
- Data is fully typed
- Data fits in a table
Disadvantages:
- Data has to be flat
- Data is stored in a database, and data definition will be different for each database
JSON (JavaScript Object Notation)
Advantages:
- Data can take any form (arrays, nested elements)
- JSON is a widely accepted format on the web
- JSON can be read by pretty much any language
- JSON can be easily shared over a network
Disadvantages:
- Data has no schema enforcing
- JSON Objects can be quite big in size because of repeated keys
- No comments, metadata, documentation
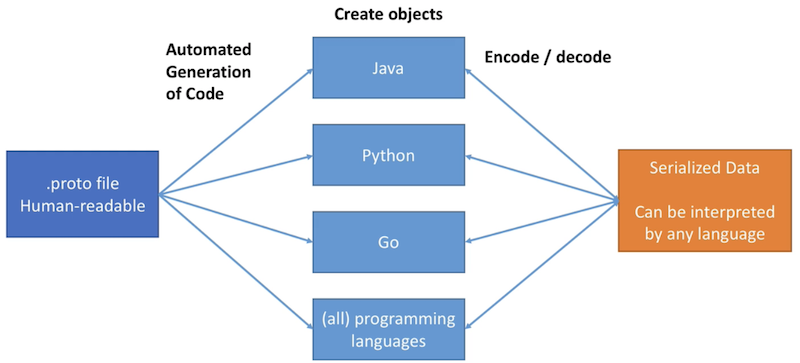
Protocol Buffers
Protocol Buffers is defined by a .proto text file. You can easily read it and understand it as a human.
Advantages:
- Data is fully typed
- Data is compressed automatically (less CPU usage)
- Schema (defined using .proto file) is needed to generate code and read the data
- Documentation can be embedded in the schema
- Data can be read across any language (C#, Java, Go, Python, Javascript, etc…)
- Schema can evolve over time, in a safe manager (schema evolution)
3-10xsmaller,20-100xfaster than XML- Code is generated for you automatically!
Disadvantages:
- Protobuf support for some languages might be lacking (but the amin ones is fine)
- Can’t “open” the serialized data with a text editor (because it’s compressed and serialised)
To share data accross languages!
Message structure
// We are using proto3
syntax = "proto3";
// In Protocol Buffers we define message
message MyMessage {
// Field Ttype, Field Name, Field Tag (e.g. Number)
int32 id = 1;
string first_name = 2;
bool is_validated = 3;
}
Default Vlaues for fields
All fields, if not specified or unknown, will take a default value
- bool: false
- number (int32, etc…): 0
- string: empty string
- bytes: empty bytes
- enum: first value
- repeated: empty list
Enums
- If you know all the values a field can take in advance, you can leverage th Enum type
The first value of an Enum is the default value- Enum must start by the tag 0 (which is the default value)
Example
// simple.proto
syntax = "proto3";
package simple;
option go_package="simple/simplepb";
message SimpleMessage {
int32 id = 1;
bool is_simple = 2;
string name = 3;
repeated int32 simple_list = 4;
}
> protoc -I . --go_out=. simple/simplepb/simple.proto
// main.go
func main() {
sp := doSimple()
}
func doSimple() *simplepb.SimpleMessage {
sp := simplepb.SimpleMessage{
Id: 12345,
IsSimple: true,
Name: "My Simple Message",
SimpleList: []int32{1, 2, 3, 4},
}
fmt.Println(sp)
sp.Name = "I renamed you"
fmt.Println(sp)
fmt.Println("The ID is: ", sp.GetId())
return &sp
}
❯ go run main.go
0 [] 12345 true My Simple Message [1 2 3 4]
0 [] 12345 true I renamed you [1 2 3 4]
The ID is: 12345
Check out the GitHub repository for more info.